Machine Learning Infrastructure: Enhancing Model Training and Deployment




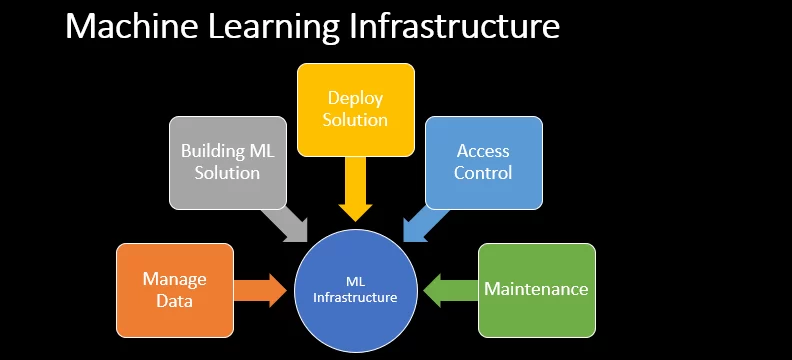
Machine Learning Infrastructure plays a pivotal role in the advancement of AI technologies, empowering organizations to train and deploy models more efficiently. By streamlining machine learning workflows, these infrastructures help bridge the gap between data scientists and DevOps teams, enabling a more collaborative and effective approach to model development. The essence of this infrastructure lies in its ability to manage vast datasets, complex algorithms, and computational resources, thereby accelerating the path from experimentation to production.
At its core, the infrastructure encompasses a variety of tools and technologies designed to automate and optimize the phases of machine learning workflows. This includes everything from data preprocessing and model training to validation and deployment, ensuring that models are not only accurate but also scalable and easily integrated into existing systems. Such a framework fosters an environment where continuous improvement and iteration are possible, allowing for the rapid evolution of models in response to changing data patterns or business needs.
Moreover, the integration of machine learning infrastructure facilitates a more agile approach to model deployment. By leveraging containerization and orchestration tools, DevOps teams can swiftly deploy models across diverse environments, ensuring consistent performance and scalability. This agility is crucial for businesses looking to stay ahead in a rapidly evolving digital landscape, where the ability to quickly adapt and innovate can be a significant competitive advantage.
However, building and maintaining a robust machine learning infrastructure is not without its challenges. It requires a deep understanding of both the technical and operational aspects of machine learning, as well as a commitment to ongoing learning and adaptation. Despite these challenges, the benefits of a well-architected machine learning infrastructure—faster model development, improved performance, and increased agility—are too significant to overlook, making it an essential investment for any organization serious about leveraging AI and machine learning at scale.
Building the Foundation: What Is Machine Learning Infrastructure?
Machine learning infrastructure provides the framework necessary to efficiently train models and manage machine learning workflows. It encompasses a wide range of technologies and processes, from data ingestion and processing to model selection and deployment. At its foundation, this infrastructure supports the ability to collect data, process data, and prepare data sets for model training. Utilizing pipelines and data lakes, alongside highly performant ingestion tools, it enables data to be automatically fed into machine learning workflows. This automation not only streamlines the entire process but also ensures that models are trained on the most relevant and up-to-date data, enhancing their accuracy and effectiveness.
Key Components of ML Infrastructure
The backbone of any machine learning infrastructure consists of several key components, each serving a distinct purpose. Training data is vital, providing the raw material from which deep learning models and traditional ML algorithms learn and improve. Volumes of data are processed and stored efficiently, thanks to cloud infrastructure, which offers scalable resources to handle the demands of machine learning operations. Infrastructure management plays a crucial role in orchestrating these elements, ensuring that resources are utilized effectively and that the infrastructure can support the growing needs of the organization. Together, these components form a cohesive ecosystem that enables the development and deployment of sophisticated machine learning models.
Exploring Learning Frameworks and Hybrid Environments
Deep learning frameworks are integral to modern machine learning infrastructure, offering libraries and tools that simplify the development of complex models. These frameworks provide pre-built functions and structures for designing, training, and validating deep learning models, making it easier for data scientists to implement cutting-edge algorithms. Whether it’s TensorFlow, PyTorch, or another popular framework, each offers its unique advantages, catering to different needs and preferences within the machine learning community.
Hybrid environments further enhance the flexibility of machine learning infrastructures. By combining on-premises resources with cloud-based services, organizations can leverage the strengths of both worlds. This approach allows for the efficient handling of sensitive data on-premises while taking advantage of the scalability and computational power of the cloud for training more demanding deep learning models. The synergy between different environments and frameworks enables a more robust and adaptable infrastructure, capable of meeting the diverse needs of machine learning projects.
The Role of Deep Learning in Modern ML Infrastructure
Deep learning has revolutionized the field of machine learning, pushing the boundaries of what ml applications can achieve. By facilitating the development of end-to-end ml solutions, deep learning has enabled more sophisticated and intelligent applications. This shift has necessitated a reevaluation of the underlying infrastructure to support the increased complexity and computational demands of deep learning models. As a result, modern ML infrastructure must be designed with the capabilities to efficiently train, deploy, and manage these advanced models.
Infrastructure Requirements for Deep Learning
The infrastructure needed for deep learning goes beyond traditional computing resources. It requires high-performance GPUs, such as NVIDIA GPUs, which are crucial for accelerating the training of deep learning models. These GPUs are specifically designed to handle the parallel processing tasks that are common in deep learning, making them a core component of any deep learning infrastructure. Additionally, the infrastructure must support end-to-end ml workflows, enabling seamless transitions from data preparation to model training and deployment for complex ml applications.
Compute and Networking Needs for Efficient Training
Efficient training of deep learning models requires a robust compute infrastructure capable of handling massive datasets and complex computations. This is where high-performance computing (HPC) systems, equipped with powerful processors and GPUs, come into play. They provide the raw computational power needed to process and analyze large volumes of data quickly. Additionally, a high-speed networking infrastructure is crucial to facilitate the transfer of data between different parts of the system without bottlenecks, ensuring that the hardware resources are utilized efficiently.
Moreover, the training process often involves distributing tasks across multiple GPUs or even across different physical locations. This distributed training approach necessitates an advanced networking setup that can handle the synchronization of data and computations across the network with minimal latency. Effective resource allocation strategies are also vital to balance the workload and optimize the use of computational resources, ensuring that each part of the system contributes to the training process without causing delays or inefficiencies.
Real-Time Inference and Its Impact
Real-time inference capabilities are transforming how ml applications interact with the world, allowing them to provide immediate insights and responses based on live data. This capability is particularly important for applications requiring instant decision-making, such as autonomous vehicles or real-time fraud detection systems. To support real-time inference, the underlying ML infrastructure must be highly responsive and capable of processing new data inputs quickly. This necessitates not only powerful computing hardware but also efficient end-to-end ml workflows that can streamline the path from data input to actionable output.
Speed and Scalability in Deploying Deep Learning Models
Deploying deep learning models at scale presents unique challenges, requiring infrastructure that can adapt to varying demands without compromising on speed or accuracy. Effective resource allocation becomes critical, ensuring that computational resources are dynamically assigned based on the model’s requirements and the current workload. This adaptability allows for the efficient handling of peak loads and ensures that the infrastructure can scale up or down as needed, providing a cost-effective solution for deploying deep learning models.
Additionally, the infrastructure must be designed to minimize latency, enabling the rapid deployment of models and quick responses to data inputs. This involves optimizing the data pipeline and computational processes to reduce delays and ensure that models can deliver real-time or near-real-time outputs. By focusing on speed and scalability, organizations can ensure that their deep learning models are both effective and efficient, capable of meeting the demands of modern ml applications.
Operationalizing ML in Hybrid and Distributed Environments
As machine learning continues to evolve, operationalizing ML in hybrid and distributed environments has become crucial for businesses looking to leverage the power of ml model training at scale. These environments combine on-premises, cloud, and edge computing resources, offering flexibility and scalability in the training process. This approach allows organizations to utilize the best available resources, reducing costs and improving efficiency by distributing the workload across different environments.
Managing Large Datasets and Training with Tools like Dask
Handling large datasets and efficiently conducting ml model training in distributed systems requires sophisticated tools like Dask. Dask enables scalable analytics by allowing data scientists to process and analyze large volumes of data in parallel, leveraging multiple cores or even distributed clusters. This capability is essential for managing the training process in environments where data is vast and computational resources are spread across different locations. By using Dask, organizations can dramatically improve the speed and efficiency of their data processing and model training efforts.
Strategies for Data Preparation in Distributed Systems
Data preparation is a critical step in the machine learning pipeline, especially in distributed systems where data consistency and accessibility can be challenging. Effective data ingestion strategies are required to gather and prepare data from various sources, ensuring it is clean, formatted correctly, and ready for analysis. This often involves processes like normalization, transformation, and feature extraction, which must be conducted efficiently across distributed environments to maintain data consistently.
Additionally, managing data across these systems requires robust data governance policies to ensure data quality and compliance. By implementing strategies that prioritize data ingestion, consistency, and governance, organizations can streamline their data preparation efforts in distributed systems, laying a strong foundation for successful ml model training.
MLOps Best Practices for Seamless Integration
Implementing MLOps best practices is essential for achieving seamless integration of ml models in production. This involves establishing robust version control systems, optimizing ml workflows, and leveraging distributed computing to streamline model deployment. By doing so, machine learning engineers can ensure that models are efficiently updated and maintained, reducing downtime and enhancing performance. Furthermore, MLOps practices facilitate collaboration among teams, promoting a more agile and responsive development process.
Building an MLOps Visibility Tool for Enhanced Server Utilization
Developing an MLOps visibility tool is key to achieving enhanced server utilization and operational efficiency. Such a tool enables teams to monitor the performance of their ML infrastructure in real-time, identifying bottlenecks and optimizing resource allocation. By providing insights into how models are trained, how data ingestion occurs, and how model selection is made, these tools help ensure that the infrastructure is highly performant. This includes tracking the efficiency of data pipelines and data lakes, as well as the effectiveness of ingestion tools.
Additionally, an MLOps visibility tool can enable data for model training to be collected and processed more efficiently, automating machine learning workflows and streamlining the end-to-end process. Organizations can leverage these insights to make informed decisions about how to best allocate resources, when to train models, and how to adjust their ML strategies to maximize performance and minimize costs.
The Future of Machine Learning Infrastructure
The future of machine learning infrastructure is closely tied to the collaboration between DevOps teams and machine learning specialists, striving to train and deploy models more efficiently. As organizations seek to harness the full potential of ML, the infrastructure will evolve to support more automated, scalable, and intelligent platforms, enabling rapid development and deployment of advanced models.
Anticipating Changes in ML Infrastructure Needs
As machine learning technology advances, anticipating changes in ML infrastructure needs becomes critical for staying ahead. Organizations must remain agile, ready to adapt their infrastructure to accommodate new computational paradigms, data processing techniques, and evolving ML models. By proactively planning for these changes, businesses can ensure that their ML infrastructure remains robust, scalable, and capable of supporting the next generation of ml applications.
Planning for Data-Driven Infrastructure and Capacity Planning
Effective data-driven infrastructure and capacity planning are essential for supporting the growing demands of ML projects. This involves leveraging data analytics to predict future resource needs, ensuring that the infrastructure can scale to meet the demands of increasingly complex models and larger datasets. By understanding usage patterns and performance metrics, organizations can make informed decisions about when to scale resources up or down, optimizing for both performance and cost.
Additionally, capacity planning must consider the evolving landscape of data privacy regulations and the need for secure data storage and processing capabilities. By integrating these considerations into their infrastructure planning, organizations can build a flexible and scalable foundation that supports the rapid development and deployment of ML models while ensuring compliance with regulatory requirements.
The Evolution towards Automated and Intelligent ML Platforms
The evolution towards automated and intelligent ML platforms is set to redefine the landscape of machine learning infrastructure. Tools like Microsoft Azure, ML Flow, and Apache Airflow are leading the charge, offering integrated solutions that streamline ml pipelines from data collection to model deployment. These platforms are designed to automate many of the tedious and complex tasks associated with machine learning, enabling faster development cycles and more efficient use of resources. As these platforms continue to mature, they will play a pivotal role in making machine learning more accessible and impactful across various industries.
How AWS and Other Platforms Support ML Infrastructure Expansion
Amazon Web Services (AWS) and similar platforms play pivotal roles in facilitating the expansion of ML infrastructure by providing a vast array of services tailored to machine learning needs. These platforms offer scalable storage options and computing power essential for handling large amounts of data and training complex machine learning algorithms. They make deploying models into production systems more seamless, integrating with existing infrastructure while ensuring efficiency and scalability of machine learning workloads.
Moreover, AWS and its counterparts support the development of ML infrastructure by offering tools and services that streamline the entire lifecycle of ML development. From data preprocessing and model training to deployment and monitoring in production environments, these platforms provide the necessary components for efficient machine learning systems. Their managed services reduce the burden on software engineering teams, facilitating the swift movement of models into production and enabling continuous improvement of machine learning experiments.
Conclusion: Navigating the Evolving Landscape of Machine Learning Infrastructure
The landscape of machine learning infrastructure is continually evolving, driven by advancements in technology and the growing demands of modern ML applications. As organizations strive to build and manage effective ML infrastructure, the focus has shifted towards creating scalable, efficient systems capable of supporting complex machine learning experiments and production workloads. This includes the adoption of hybrid environments, leveraging the power of cloud computing, and the integration of MLOps practices to streamline the transition of models from development to production.
Success in this dynamic field requires a deep understanding of the key components and challenges of ML infrastructure. Organizations must remain agile, ready to adopt new tools and practices that enhance the efficiency and effectiveness of their machine learning systems. Embracing these challenges and opportunities will be crucial for businesses looking to harness the full potential of machine learning and maintain a competitive edge in the era of AI-driven innovation.
Key Takeaways for Building and Managing Effective ML Infrastructure
In building and managing effective ML infrastructure, several key takeaways stand out. Utilizing the right tools and frameworks is essential for ensuring models are trained efficiently, leveraging GPU memory and distributed file systems for optimal performance. Engineering teams must focus on the entire lifecycle of ML algorithms, from raw data processing to deploying models to production. An infinitely scalable ML platform supports training and deploying ML models across various applications, including autonomous vehicles and computer vision, enhancing infrastructure implementations with powerful visualization tools for deeper insights.
Embracing the Challenges and Opportunities Ahead
The journey towards building robust ML infrastructure is fraught with challenges, from managing vast amounts of data to ensuring models perform accurately in production environments. Yet, these challenges present opportunities for innovation and improvement. By focusing on scalable solutions, continuous learning, and the integration of AI into software engineering practices, organizations can overcome these hurdles. This forward-thinking approach will enable the development of more sophisticated and efficient machine learning systems, capable of addressing the complex needs of modern applications.
As the field of machine learning continues to evolve, staying ahead of the curve will require a commitment to learning and adaptation. The dynamic nature of ML technology demands that organizations remain flexible, open to adopting new methodologies, and ready to leverage advancements in neural networks and machine learning algorithms. Embracing these changes will not only enhance ML infrastructure but also pave the way for groundbreaking innovations in AI.